


文章の中に出てくる頻出単語のカウント方法です。
シンプルな分析ではありますが、頻出単語が分かるだけでもその文章データの持つ傾向を大まかに知ることができます。
今回は例題として、夏目漱石「こころ」に出てくる頻出単語ランキングをPythonで作成してみます。
(データは青空文庫から拝借いたしました。)
データの読み込み
まずはデータを取り込みます。
取り込むデータによっては表記揺れ対策などのデータクレンジングが必要です。
が、本記事のメインテーマではないのでそちらに関しては下記の記事をご参照ください。
今回は、青空文庫の内容をテキストに書き出したものを読み込みます。
|
1 2 3 4 |
#夏目漱石「こころ」の取り込み f = open('kokoro.txt') text = f.read() # ファイル終端まで全て読んだデータを返す f.close() |
これで、変数textに文章すべてが格納されます。滅茶苦茶長い文字列になりますが、これくらい(約23万字)なら難なく処理できます。
形態素解析の実行
形態素解析というのは文章を単語ごとに分割する作業の事を言います。
英語などは単語ごとにスペースが入っているのでこの作業は不要ですが、日本語や中国語においてはまず「文章を単語ごとに分割」する作業が必要です。
形態素解析を行えるライブラリは色々ありますが、今回はMeCabを用いて分割してみます。
※Janomeにおける実行はこちらにて。
ちなみに、新語を多数追加した「mecab-ipadic-neologd」というパッケージもあるのですが、今回用いるのは大正時代の文学ということで敢えて使わないでおきます。
(試しにやってみたのですが、「あなたに」で一語になってしまったりします。おそらく同名の曲名があるので、固有名詞と判断されたのでしょう。)
|
1 2 3 4 5 6 7 8 9 |
#MeCabで分割 import MeCab m = MeCab.Tagger ('-Ochasen') node = m.parseToNode(text) words=[] while node: words.append(node.surface) node = node.next |
「node.surface」は次々と単語を取得してゆくことができ、それを「words」というリストにどんどん追加していきます。
print(words)とすると、
|
1 |
['私', 'など', 'は', 'とても', '使う',... |
と、文章が単語ごとに分割されている事が分かると思います。
頻出単語のカウント
方法は多々ありますが、最もポピュラーで簡単なのはcollectionsメソッドを使用する方法でしょう。
|
1 2 3 4 |
#単語の数カウント import collections c = collections.Counter(words) print(c.most_common(20)) |
これだけです。
most_common()メソッドを用いると、使われている回数が多い単語から順番に取得できます。
カッコの中に数字を入れれば、使われている回数が多い方から順番にn個だけ取ることができます。
つまり上の書き方だとTOP20が取得できます。
では結果を見てみましょう。
|
1 |
[('た', 2038), ('。', 1901), ('の', 1885), ('は', 1600), ('に', 1362), ('て', 1170), ('、', 1108), ('私', 1098), ('を', 1084), ('が', 829), ('と', 723), ('\u3000', 682), ('「', 603), ('」', 557), ('で', 527), ('し', 512), ('も', 483), ('ない', 455), ('です', 446), ('先生', 356)] |
使用頻度が多い単語と、その回数がペアで取得できていますね。
使用する品詞を絞る
さて、上の結果を見ると、「てにをは」のような助詞など、「そりゃ多いよね」という言葉ばかりです。
どうも、使う品詞を絞ってあげたほうが良さそうです。
ということで、単語を抽出する段階で、指定した品詞の単語だけ取ってくるようにしましょう。
今回は試しに、名詞・動詞・形容詞だけを取り出してみます。
また、「来る」「来て」「来たら」など、活用が違うだけで原型は同じ単語も1つとして数えたい所です。
以上を踏まえて、単語抽出のメソッドを少々作り変えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#MeCabで分割 import MeCab m = MeCab.Tagger ('-Ochasen') node = m.parseToNode(text) words=[] while node: hinshi = node.feature.split(",")[0] if hinshi in ["名詞","動詞","形容詞"]: origin = node.feature.split(",")[6] words.append(origin) node = node.next |
「node.feature」には単語の品詞などの情報がカンマ区切りで入っています。
0番目に品詞名、6番目に原型データが入っています。
それを踏まえて、node.featureの0番目が名詞・動詞・形容詞だったらその6番目をピックアップする、という処理になっています。
あとは同様に、collectionsメソッドを使うと。。。
|
1 |
[('私', 1098), ('する', 657), ('いる', 494), ('の', 465), ('先生', 356), ('いう', 276), ('事', 238), ('なる', 216), ('ある', 200), ('よう', 178), ('奥さん', 176), ('ん', 175), ('それ', 166), ('人', 142), ('もの', 142), ('時', 141), ('父', 134), ('来る', 132), ('れる', 128), ('思う', 115)] |
これだと、先ほどと違って文章の特徴が取れているように見えます。
これだけで文中に出現する登場人物などはよく分かるようになりました。
あとは「”する”、”いる”などの動詞も排除した方がよいかな」「名詞の中でも”一般名詞”、”固有名詞”」など色々あるので、それも絞ろうかな」など、扱うデータや欲しい分析結果によって場合場合で対応していきましょう。
結果のグラフ化
最後に、結果をグラフにして分かりやすく表示してみます。
seabornのcountplotメソッドを使えば簡単です。
|
1 2 3 4 5 6 7 |
import seaborn as sns import matplotlib.pyplot as plt sns.set(context="talk") fig = plt.subplots(figsize=(8, 8)) sns.countplot(y=words,order=[i[0] for i in c.most_common(20)]) |
引数として「単語をリストに格納した変数」(今回で言えばwords)を与えれば、単語の数をカウントしてくれます。
また、出現回数が大きい順に並び替えた方が見やすいので、引数orderにて先ほど取得した頻度情報の単語の部分だけを指定しています。
グラフの見た目はお好みで。
結果は・・・
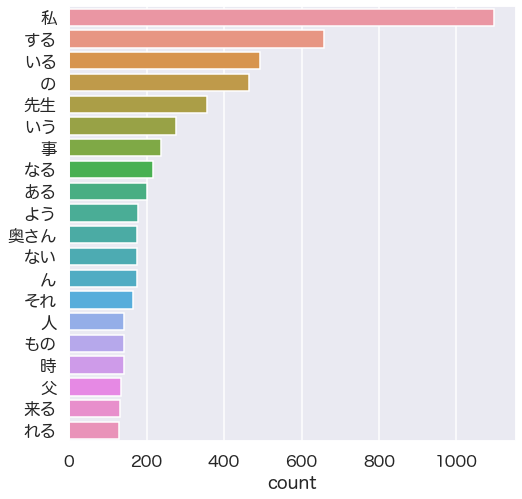

これで、文章中の単語の出現傾向が”パッと見”で分かりやすくなりました。
さいごに
頻出単語の抽出はテキストマイニングの中でも基本的な技術ですが、その効果は絶大です。
たとえば大量の自由文アンケートで、年代別、性別別などで使われる単語の傾向を調べたり、なんていう事もすぐできます。
この作業をExcelでやるのは大変ですが、Pythonでは簡単ですので、是非使ってみてください。