
PythonによるCSV/TSVの読み込みとデータの取得方法
Pythonでデータ分析をする為の「第一歩」として、CSV/TSVデータをPythonに読み込む方法を見ていきます。
※ちなみに、CSVは「Comma Separated Values」つまりカンマで区切られたデータという意味、
TSVは「Tab Separated Values」つまりタブで区切られたデータという意味です。
方法は何通りかありますが、私は断然、pandasライブラリを用いた方法をオススメします。
CSV/TSVを読み込む
まず、pythonスクリプトがあるフォルダと同じフォルダに、読み込みたいCSVファイルをコピーします。
(無論、パスを指定すればどのフォルダにあっても参照できます)
今回は以下のような、社員別の給与CSVデータ「salary.csv」を読み込んでみましょう。
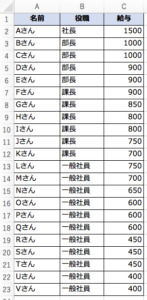
|
1 2 3 |
import pandas as pd df = pd.read_csv("salary.csv") print(df) |
読み込みたいファイルがCSVではなく、TSVであれば以下のようにseqオプションを付けます。
|
1 2 3 |
import pandas as pd df = pd.read_csv("salary.csv",sep='\t') print(df) |
スクリプトを実行すると…。
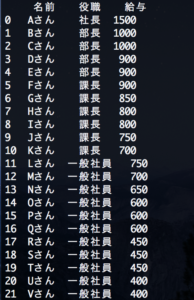
きちんと読み込まれているようです。
また、読み込むファイルの文字コードによっては以下のようなエラーが出て、うまく読み込めない場合がありますので注意しましょう。
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x8e in position 1: invalid start byte
(この場合はおそらく、読み込むファイルの文字コードを「UTF-8」に変更すれば正しく読み込めます。)
データを取得する
正しく読み込めているのか、読み込んだデータから要素を取得してみましょう。
試しに「Aさんの役職」を抽出します。
その場合は、
|
1 |
print(df[df["名前"]=="Aさん"]["役職"]) |
この書き方で、“名前”が「Aさん」である行の”役職”を取り出すという意味になります。
結果は・・・
![]()
正しく取り出せているようです。
同様に、“役職”が「部長」である行の”給与”を取り出したければ、
|
1 |
print(df[df["役職"]=="部長"]["給与"]) |
結果は・・・

このように、条件を満たす要素を複数取り出すこともできます。
以上、CSV/TSVの読み込みと、簡単なデータの取得方法でした。

