AIシステムの性能要件の中には、一般的なITシステムの性能要件に加え、「AIの精度」という大事な項目が含まれます。
処理性能であればそのハードウェアの性能を前提条件として付しておかないといけないのと同じように、AIの精度に関してもその「前提条件」を定義し、そしてその定義の妥当性に関してきちんと決定、顧客説明、そして合意せねばなりません。
具体的には、
・性能指標
・データ
この2点を明確化します。これらをいい加減に決めてはいけません。
これらを正しく決定して、後々問題を起こさぬためのひとつの考え方を本記事では提示できればと思います。
それでは、今回は仮にフルーツの画像を認識して、「リンゴ」「ミカン」のいずれなのかを自動判別し、タグ付けするシステムの精度要件を考えてみましょう。
「性能指標」・・・精度の「分母」「分子」は妥当か?
精度は基本的に割合(%)で計算されます。割合ということは、必ず「分母」と「分子」が存在しています。
この「分母」と「分子」を明確にすることが、正しく性能を測るための第一歩です。
では、上記のシステムにおいて分母と分子はどう定義すれば良いでしょうか。
正解率を指標としてみる
まず、単純に考えられるのは「正解した数/全画像数」という指標でしょう。
これは一般的に「正解率」と呼ばれる指標です。
これで問題ないようにも見えますが、実は問題があります。
リンゴの画像数とミカンの画像数が大きく異なっていたらどうなるでしょう。
リンゴの画像数は1000枚で、そのうち正解が900枚。
ミカンの画像数は10枚で、そのうち正解が2枚。
リンゴは9割正解していますが、ミカンは2割しか正解していません。
しかし、これらを合計すると、「1010枚中、902枚正解」となるので精度は約89%です。
結果がリンゴに引っ張られ、「ミカンの性能が悪い」という事が全く分からなくなってしまいます。
これを「精度89%」のシステムと言い張ってしまうと、いざ、ミカンを判別しようとした際の性能がボロボロで、「どこが89%なの?!」と文句を言われても仕方ありません。
単純に「正解率」を指標としただけなのに、下手をしたら嘘の精度を伝えられたと思われてしまう可能性すらあります。
ということで、モノによって枚数が大きく異なる場合、「正解率」はあまり良くない事が分かりました。
再現率を指標としてみる
さて、全ての果物を引っくるめて精度を計算すると問題がある事が分かったので、お次は果物ごとにどれだけ正解できたかを見てみます。つまり、
「リンゴの正解数/リンゴの画像数」
「ミカンの正解数/ミカンの画像数」
をそれぞれ出して、それらを平均したものをこの「AIの性能」としてみます。
これは「再現率」と呼ばれる指標です。
上の例で言えば、リンゴの精度は90%で、ミカンの精度は20%です。
この数値を出しておけば、ミカンの精度に納得して頂けるかは別として、性能要件で嘘を書いているとは思われないでしょう。
ただし、果物が2種類くらいならば、それぞれの再現率を並べて伝えれば良いのでしょうが、果物が100種類ということになってくるとそうもいきません。こういう場合は、100種類の再現率の平均値をひとまず「AIの精度」とした上で、補足資料として果物別の精度を出しておけば良いでしょう。
何にしても、今回の例においては、「再現率」は「正解率」よりも良い指標になりそうです。
・・・が、しかしこれでもまだ問題があるのです。何でしょうか。
今回、判別したい画像はあくまで「果物の画像」です。
それには、ブドウ、モモ、スイカ、メロン…と、判別対象外の果物も存在すると考えるのが普通です。
しかし今回のAIは「リンゴ」「ミカン」しか判別しません。
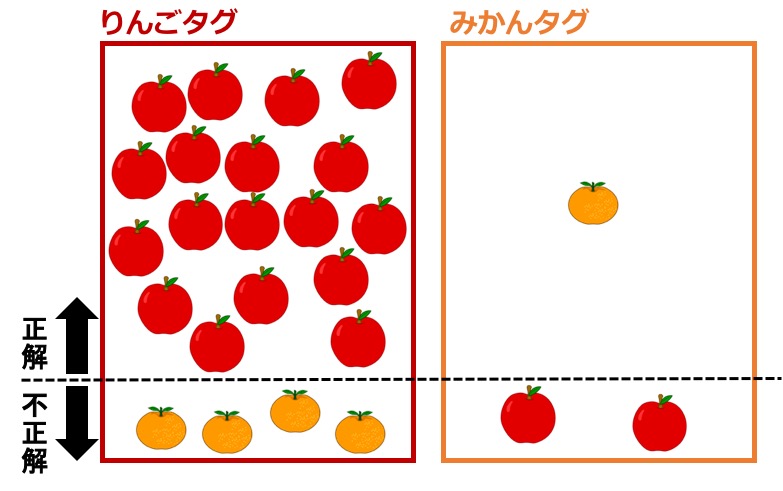
つまり、下図のようにブドウやモモなどの画像にもリンゴタグorミカンタグが振られてしまう訳です。
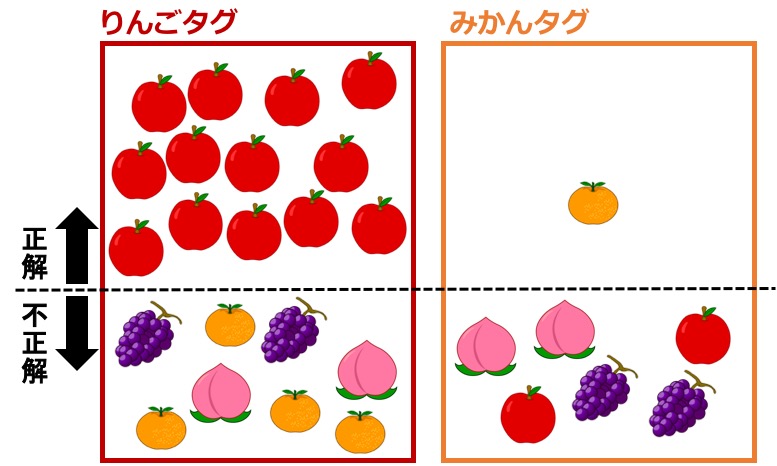
ユーザからすると、「リンゴとタグ付けされた画像一覧」に、ブドウやモモなども含まれてしまっているわけで、しかも、ブドウやモモの画像が何枚あるのかも分かりません。
再現率は所詮、「リンゴ1,000枚中、900枚は正しく分類できている」という事が分かるだけであって、リンゴ以外の画像に「リンゴ」のタグが付けられてしまっている枚数の事は分からないのです。
「リンゴ」タグが付けられた画像数が何千枚もあるのかもしれません。
しかし、その中にリンゴの画像は900枚しかない。
これまた、「リンゴの精度90%」という情報が嘘ではないのに嘘に見えてしまいます。
こういった状況の対処はどうすれば良いでしょうか。もう1つ、別の指標を考えてみます。
適合率を指標としてみる
適合率とは、
「リンゴの正解数/リンゴタグが付けられた画像数」
「ミカンの正解数/ミカンタグが付けられた画像数」
という指標です。
「リンゴタグ」の一覧画面にリンゴが何枚あるのか、「ミカンタグ」の一覧画面にミカンが何枚あるのか、とも読み替えられます。
これはユーザの体感的な精度に近いですね。
ちなみに本件のみならず、ユーザの感覚を最も反映している指標は適合率である場合が多いです。
では仮にブドウとモモが各500枚あるとして、それらに等しく「リンゴ」or「ミカン」タグが振られるとします。すると、
「リンゴ」タグがついた画像はリンゴ900枚、ミカン8枚、ブドウ250枚、モモ250枚の、合計1,408枚です。
そのうち、リンゴの画像は900枚なので、リンゴの適合率は900/1,408=約64%です。
「ミカン」タグがついた画像はリンゴ100枚、ミカン2枚、ブドウ250枚、モモ250枚の、合計602枚です。
そのうち、ミカンの画像は2枚なので、ミカンの適合率は2/602=約0.3%です。
この精度を提示しておけば、おおよそ体感の精度とは異なりません。
・・・しかし、ミカンの精度が0.3%で納得してもらえるとも到底思えません(笑)
この辺りは難しいところですが、現状リンゴとミカンしか判別できない以上、この問題はどうしようもありません。
こうなると、タグの種類が2種類では限界があるなどきちんと説明しておくべきで、
「適合率を上げたいのならば、タグの種類を増やす必要がある」などと話を持っていくのも良さそうです。
まとめ
ここで、ここまでの結果を混同行列に整理してみます。

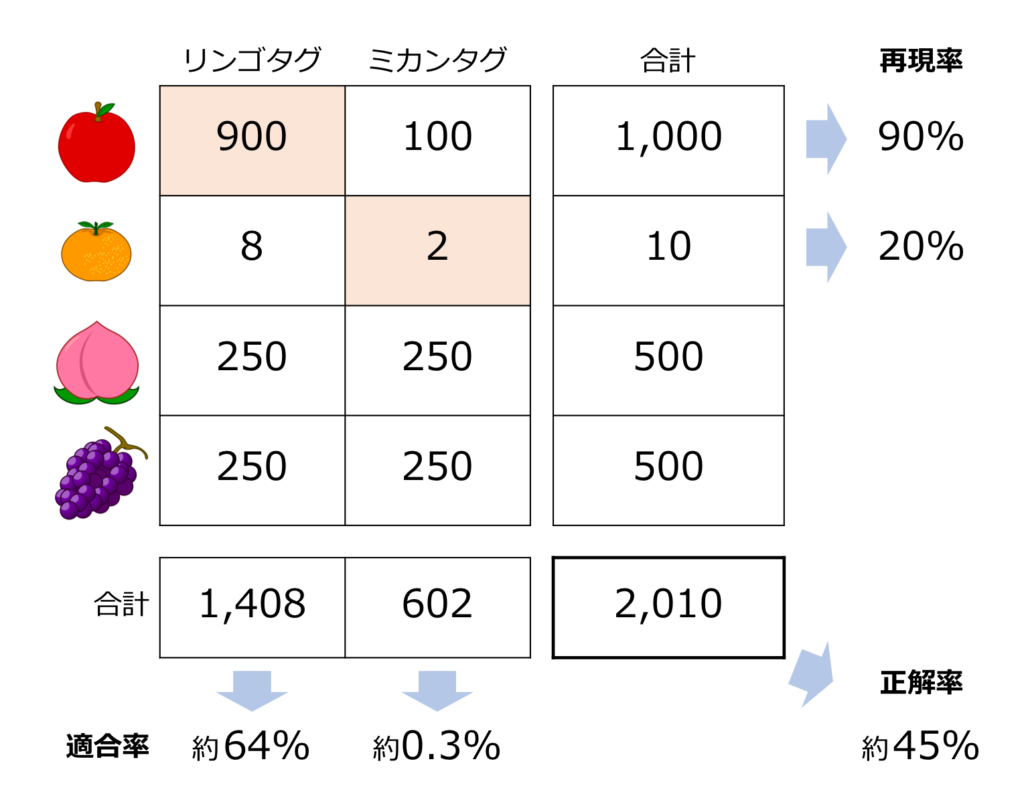
どの指標を選択するのが最適なのか、混同行列を書くと判断しやすくなります。
「分類」するAIの性能指標を考える場合はひとまず混同行列を書いてみることをおすすめします。
「データ」・・・恣意的なデータを使っていないか?
さて、上記を元に適切な指標を決定したら、お次は「どんなデータを使って評価するのか?」を決めなければいけません。
こちらの都合の良いようにデータを選んだら精度0%にだって100%にだってできてしまいます。
このあたりは、指標を何にするかによって、最適なデータセットは異なるでしょう。
例えば、「再現率」を指標とするならば、全ての果物の枚数を同じだけ準備する。
リンゴでもミカンでも全て100枚、など統一しておけば、果物ごとの判別の良し悪しが分かりやすくなります。
逆に、「適合率」を指標とするならば、より現実に即したデータを準備する。
適合率はユーザの体感に近い性能指標でしたので、それをより最適化したいのならば、データはより現実に近づけるべきです。
リンゴやミカンは多いけど、ドリアンなどの珍しい果物は母数が少ない、といった情報を反映したデータセットを作る、など・・・。
その上で、精度○○%と定める
このような視点で、「性能指標」「データ」の2つを恣意的にならないように決めます。
まずは「性能指標」を明確にして、その指標に適する「データ」を準備する。そこでやっと「このAIの精度は○○%です」と言うことができるのです。
この2点をきちんと決めてAIの精度を見積もる。
そして、その妥当性を顧客説明して、合意を頂く。
システムが稼働してから問題を起こさぬために、AIシステムの要件定義においてこのプロセスを怠ってはいけません。