
データ分析手法のひとつ「決定木分析」をPythonで実行してみます。
決定木分析は経営の意思決定などビジネスで活躍することの多い手法です。
しかし、Excelでは実行できないためか一般的に用いられているシーンはそこまで見ません。
しかし、決定木分析は非常にシンプルで強力な手法であり、Pythonを使えば簡単に実行できます。
ぜひ使いこなして頂ければと思います。
簡単に理論紹介
決定木分析とは、「要因データ」と「結果データ」がペアで存在しているデータに対して用いられる、いわゆる「教師あり学習」のひとつです。
回帰分析と一緒ですね。
ただ、回帰分析は「売上金額=1.2×気温+100」のようにデータの関係性を数式で表わせるのですが、決定木分析ではそれはできません。
その代わり、決定木分析は「気温が30度以上の場合は売上金額400円、30度未満の場合は200円」のように場合分けの関係性を表すことができます。
さらに、「気温30度以上で天気が雨の場合は・・・」など、どんどん階層を深くしていくことも可能です。
そして、決定木分析の出力は一般的に以下のような図で表されます。
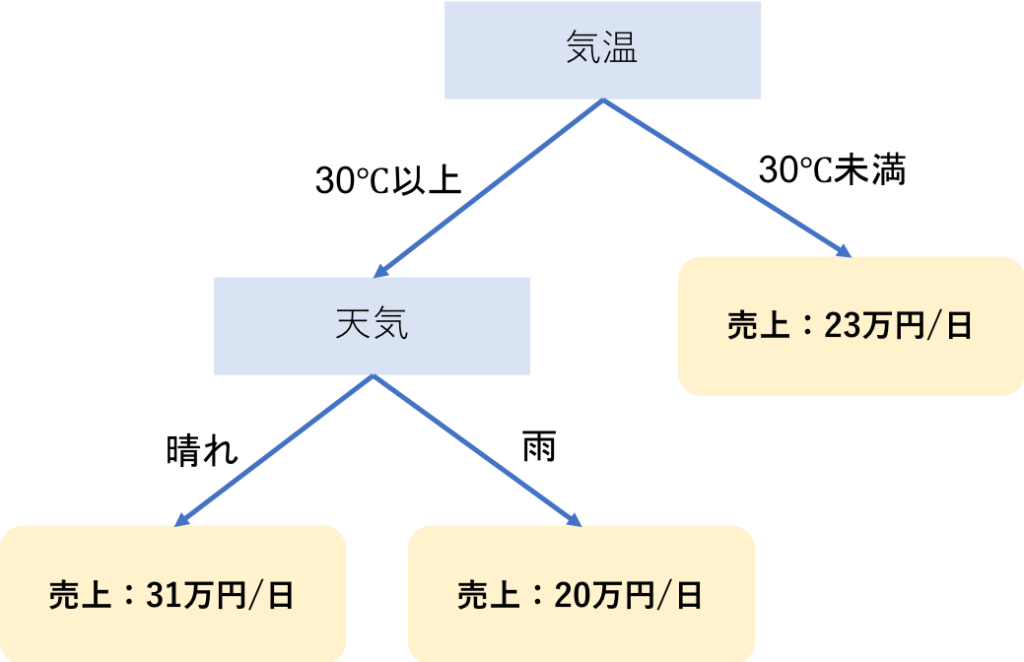
一本の枝が枝分かれしてゆく木のような構造を持つことから、こういった図を「決定木」と呼び、それを用いたデータ分析を「決定木分析」と呼びます。
回帰分析と決定木分析のどちらが優れるかは時と場合によります。
「クラスの予測がしたい時は決定木、数値の予測がしたい時は回帰分析」というのが一般的な気もしますが、どちらの手法でもクラス予測も数値予測もできます。
分類木と回帰木
さらに決定木は「分類木」と「回帰木」に分けられます。
ほとんど同じなのですが、「分類木」はクラスを予測したい時。「回帰木」は数値を予測したい時に用います。
たとえば商品が「売れるか、売れないか」を調べたい時は分類木、「いくら売れるか」を調べたい時は回帰木、という感じです。
これはデータが決まっていれば必然的に決定する部分なので、どちらを使うかで悩む必要はありません。
Pythonによる決定木分析の実行
Pythonで決定木分析を実行する方法は幾つかあるのですが、キレイな決定木が作れる「dtreeviz」というパッケージで実行してみます。
せっかくなので分類木と回帰木、どちらも作成してみます。
ファイルの読み込み
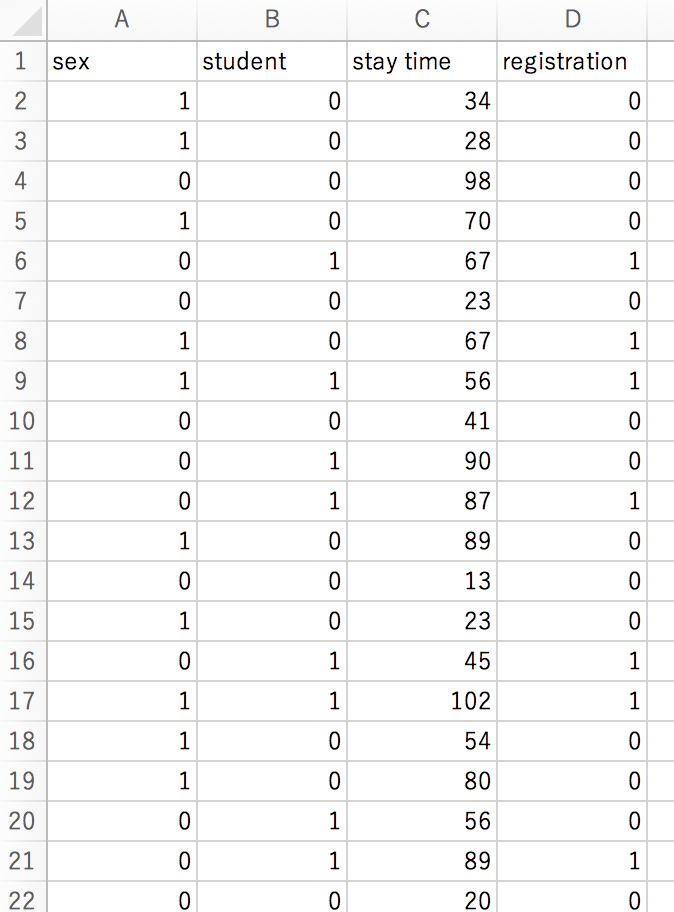
分類木にはロジスティック回帰分析の際に用いたデータと同じものを使います。
あるツールの利用者情報から、その利用者がユーザ登録してくれたかどうかを一覧化したデータです。
データの形式は以下。
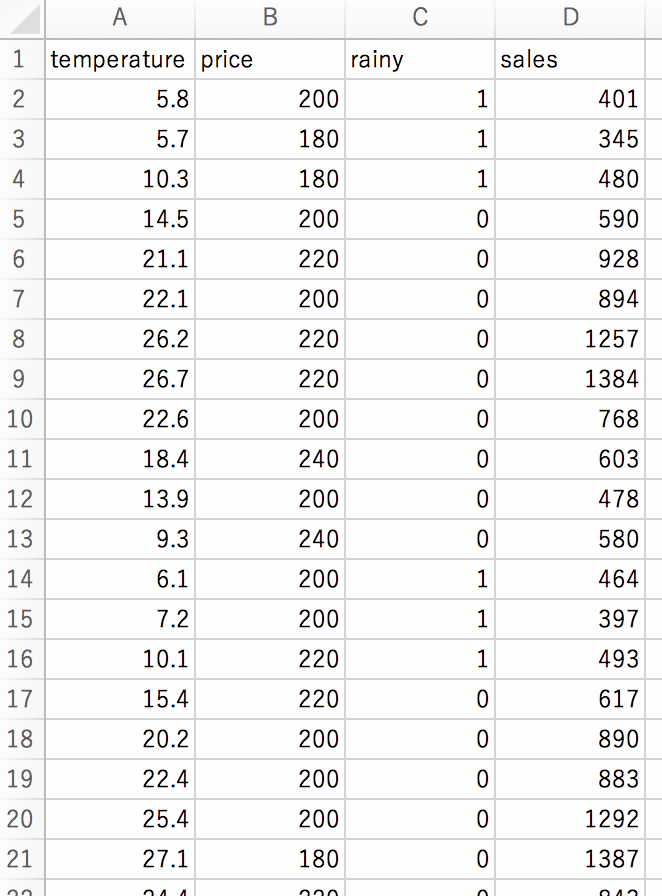
回帰木には重回帰分析の際に使ったデータと同じものを使います。
気温や天気の情報と、その日のアイスクリームの売上を一覧化したデータです。
データの形式は以下。
なお、dtreevizパッケージでは日本語の表示ができないため、列名のみ英語に変更しています。
まずは以下のようにcsvを読み込み、X(従属変数)の列とy(目的変数)の列に分離します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import numpy as np import pandas as pd #CSV読み込み df = pd.read_csv("[ファイル名]") #目的変数名の指定 y_name = "sales" #従属変数(使用列)の選択 X_name = ["temperature","price","rainy"] #Xとyに分離 X_train = df[X_name] y_train = df[y_name] |
目的変数名と従属変数名はデータに合わせて定義してください。
https://analysis-navi.com/?p=1229
https://analysis-navi.com/?p=1930
分類木の作成
まずは分類木を用いて決定木分析を実行します。
|
1 2 3 4 5 6 7 |
from sklearn.datasets import * from sklearn import tree from dtreeviz.trees import * import graphviz dtree = tree.DecisionTreeClassifier(max_depth=2) dtree.fit(X_train, y_train) |
分類木を作成する時は「DecisionTreeClassifier」メソッドを用います。
引数の「max_depth」は木の深さを表します。
今回はデータの数も特徴量の数も少ないので、深さは少なめに2にします。
決定木分析における木の深さ(max_depth)は2〜5程度に収めたほうが、解釈しやすい結果が得られる場合が多いと思います。
続いては、結果を表示してみます。
|
1 2 3 4 5 6 7 |
viz = dtreeviz(dtree,X_train,y_train, target_name='registration', feature_names=X_name, class_names=["Not Register","Register"], ) viz |
最後は「viz」とするだけで結果表示できます。
また、分類木の場合は「class_names」という引数を定義しないと実行できません。
その名の通り、ここにはクラス名を指定します。
今回の場合、「0」が「登録しない(Not Register)」、「1」が「登録する(Register)」なので、それをクラス名としました。
では、結果を見てみます。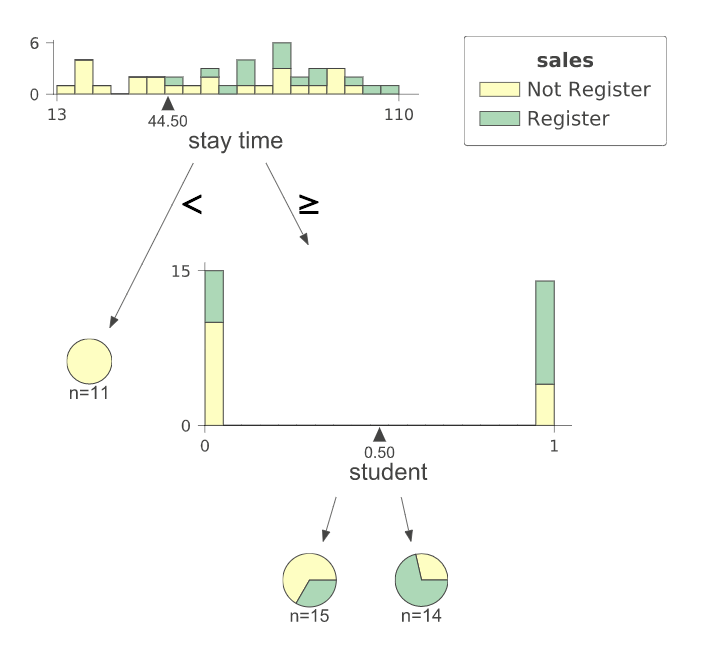
まず、「stay time」が44.5秒を上回るかどうかで場合分けされています。
下回る場合は11人中11人、誰も登録していないようです。
上回る場合は、2階層目に行きます。
次は「student」、すなわち学生かどうかで場合分けされています。
これが「0」、つまり学生でない場合は3割程度が登録してくれるようです。
逆に「1」、つまり学生の場合は7割程度が登録してくれるようです。
つまり、今回の場合「滞在時間が長い学生」がユーザ登録してくれるようだと、この図から読み取ることができます。
ちなみに、最後に「viz.save(“〜.svg”)」とすれば出力された決定木の画像を保存することができます。
(svg形式以外の出力を行うには設定が必要なようです。)
ロジスティック回帰分析でも「滞在時間」と「学生かどうか」の2つが重要と出ていましたので、似た結果が得られているようです。
回帰木の作成
続いては回帰木による決定木分析を実行してみます。
|
1 2 3 4 5 6 7 |
from sklearn.datasets import * from sklearn import tree from dtreeviz.trees import * import graphviz dtree = tree.DecisionTreeRegressor(max_depth=2) dtree.fit(X_train, y_train) |
回帰木を作成する時は「DecisionTreeRegressor」メソッドを用います。
分類木と同じく、max_depth=2とします。
結果の表示は以下。
|
1 2 3 4 5 6 |
viz = dtreeviz(dtree,X_train,y_train, target_name='sales', feature_names=X_name, ) viz |
回帰木においては「class_names」を定義する必要性はありません。
以上を実行すると・・・。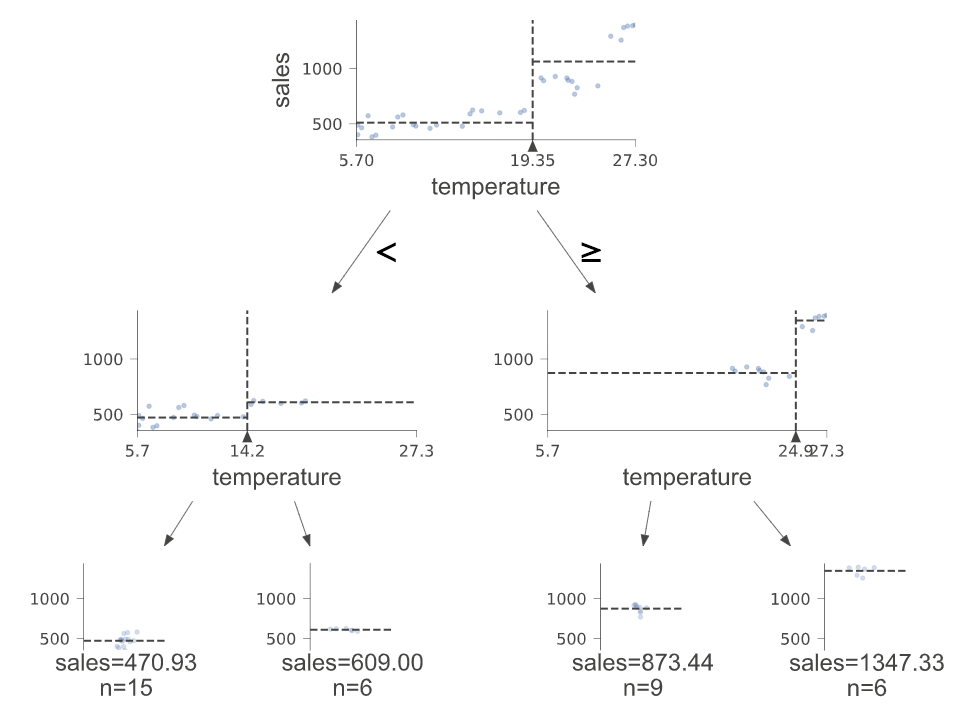
まずは「temperature」、つまり温度が19.38度を上回るかどうかで分岐があります。
続いて2段目も「temperature」のようです。
結局、温度を4パターンに分ければ良く、priceやrainyは推定に殆ど関係ないという結果が得られました。
このように、別の階層で同じ特徴量が使われる場合もあります。
これは重回帰分析の結果とは違いますが、おそらく「temperature」と「rainy」自体の相関が高いので、片方を見ておけば十分と見なされたのでは無いでしょうか。
未知データの予測
未知データの推測も行ってみます。
これにはdtreevizに便利な機能があります。
決定木を描画する時に、新たに「X」という引数を定義します。
これには、特徴量の数値を指定したリストを指定します。
たとえば、上の分類木の例を用い、性別=男性(0)、学生(1)、滞在時間(50秒)の場合はどうなるか調べてみます。
|
1 2 3 4 5 6 |
viz = dtreeviz(dtree,X_train,y_train, target_name='sales', feature_names=X_name, class_names=["Not Register","Register"], X=[0,1,50] ) |
引数Xに調べたい数値を入力しておくだけです。
これを実行すると・・・。
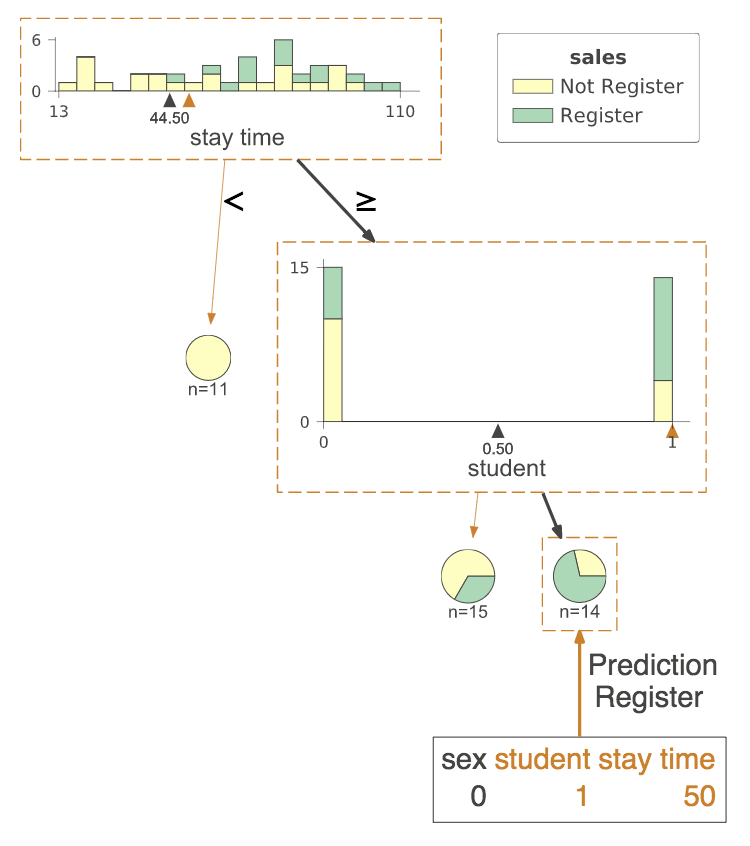
このように、オレンジ色の枠が表示されました。
男性の学生で滞在時間が50秒あれば、ユーザ登録可能性が70%ほどであるとひと目で分かるようになりました。
以上、Pythonを用いた決定木分析の実行方法でした。





