

階層型クラスタリングをPythonで実行してみましょう。
scipyのclusterというパッケージを使えば非常に簡単に作成することが出来ます。
階層型クラスタリングの理論についてはこちらをご覧ください。

データの読み込み
今回は、理論編で用いたものと同様のデータを、以下のように「clustering.csv」という名前にして読み込ませてみます。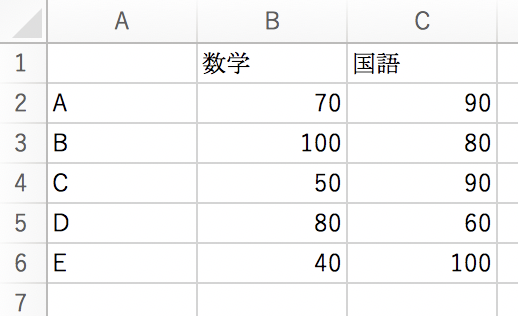
|
1 2 |
import pandas as pd df = pd.read_csv("clustering.csv",index_col=0) |
index_col=0を指定すると、csvの1列目をindexとして読み込んでくれます。
ではこのデータに対して、様々な手法で階層型クラスタリングを実行してみましょう。
階層型クラスタリングの実行
階層型クラスタリングにも色々種類がありますが、理論編で、「困ったらウォード法」と述べたとおり、まずはウォード法を用いてクラスタリングしてみます。
|
1 2 3 4 5 6 7 |
import matplotlib.pyplot as plt from scipy.cluster.hierarchy import linkage, dendrogram, fcluster linkage_result = linkage(df, method='ward', metric='euclidean') plt.figure(num=None, figsize=(16, 9), dpi=200, facecolor='w', edgecolor='k') dendrogram(linkage_result, labels=df.index) plt.show() |
これだけです。非常に簡単ですね。
linkage関数の引数methodで階層型クラスタリングの手法を選択します。
「single」が最小結合法、「complete」が最大結合法、「average」が群平均法、今回のように「ward」がウォード法となっています。
この他にも、重み付き平均法と呼ばれる「weighted」、重心法と呼ばれる「centroid」の6つの手法が用意されています。
また、引数metricで使用する距離の種類を選択します。
「距離」には実は山のように種類があるのですが、我々が一般的に「距離」と言っているものはユーグリッド距離(eulidean)なので、特段理由が無ければこれを選択しておけば良いでしょう。
最後のplt.show()により、以下のようにグラフが可視化されて表示されます。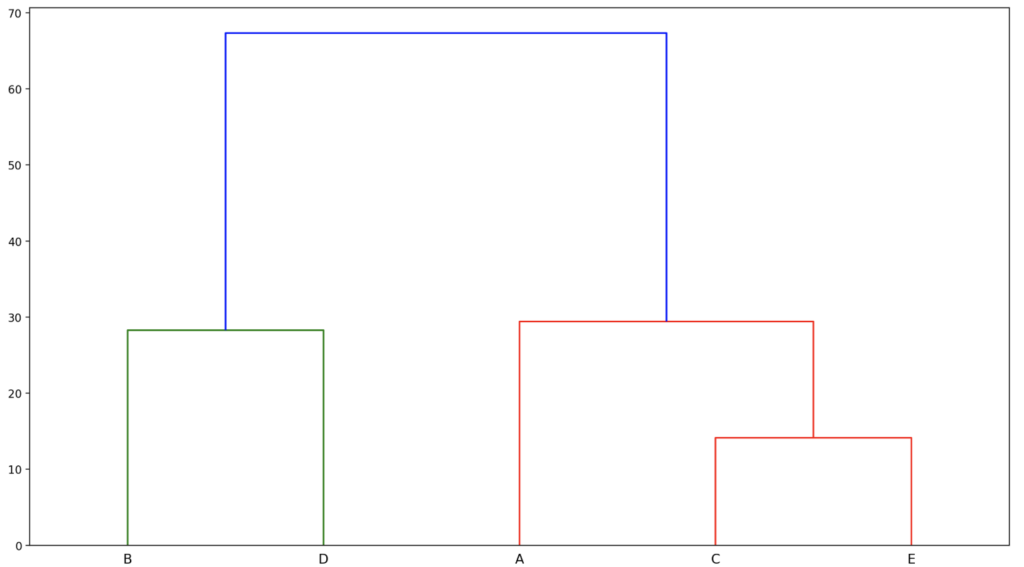
理論編で計算した時と同様のグラフが得られているようです。
(ABCDEの並び順は違いますが。)
同じように、methodに「single」「complete」「average」を選択した際にも、理論編で計算した時と同様の結果が得られます。
まとめ
クラスタリングはデータをグループ分けする際に非常に協力となる手法ですが、Excelでクラスタリングを行うのは、目下、困難です。
しかしPythonを使えば10行足らずで簡単に階層型クラスタリングが実行できます。
是非クラスタリングを活用して、データに眠る新たな価値を見出してください。
非階層クラスタリングについては以下に整理しています。





