Pythonを使って回帰分析を行ってみましょう。
理論や用語についてはこちらをご覧ください。

データの読み込み
まずは何はともあれ、データを読み込みます。
今回は「気温とアイスクリームの売上」データを読み込み、その関係性を調べてみます。
そして、それに基づいて翌日以降の予想気温からアイスクリームの売上を予測してみましょう。
ちなみに、ファイルは以下のような形式になっています。
– 既知のデータ(sales_data.csv)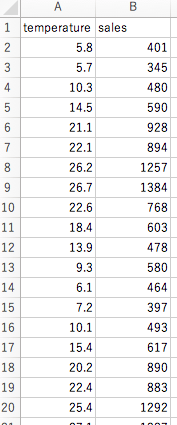
– 予測対象データ(sales_future.csv)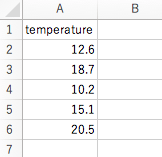
それでは、以下の通り2つのcsvを読み込みます。
|
1 2 |
df = pd.read_csv("sales_data.csv") df_test = pd.read_csv("sales_future.csv") |
続いてはsales_data.csvに基づいて回帰分析を行い、sales_future.csvに対して売上予測をしてみます。
回帰分析の実行
Pythonで回帰分析を実行するためのパッケージには幾つかあるのですが、個人的には回帰分析の実行結果が詳細に確認できる「statsmodels」をオススメします。
statsmodelsを使うと、以下のように回帰分析が簡単に実行できます。
|
1 2 3 4 5 6 7 8 9 10 11 |
#xとyに分離 x_name = "temperature" y_name = "sales" x = df[x_name] y = df[y_name] #回帰分析の実行 import statsmodels.api as sm model = sm.OLS(y, sm.add_constant(x)) result = model.fit(disp=0) print(result.summary()) |
まずは読み込んだcsvをxとyに分離します。
求めたいもの(目的変数)が「y」で、その計算に使うもの(説明変数)が「x」です。
これに関しては人間が指定してあげる必要があります。
ちなみに、「add_constant」は、切片を使う場合に指定します。つまり\(y=ax+b\)の\(b\)の項を使う場合には付けます。多くの場合は使うかなと。
そして、最後にresult.summary()をprintすると以下が表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
OLS Regression Results ============================================================================== Dep. Variable: sales R-squared: 0.808 Model: OLS Adj. R-squared: 0.803 Method: Least Squares F-statistic: 143.2 Date: Sun, 23 Jun 2019 Prob (F-statistic): 9.68e-14 Time: 17:18:11 Log-Likelihood: -228.93 No. Observations: 36 AIC: 461.9 Df Residuals: 34 BIC: 465.0 Df Model: 1 Covariance Type: nonrobust =============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------- const 106.7334 58.138 1.836 0.075 -11.417 224.884 temperature 39.1031 3.267 11.969 0.000 32.463 45.743 ============================================================================== Omnibus: 3.479 Durbin-Watson: 1.573 Prob(Omnibus): 0.176 Jarque-Bera (JB): 1.602 Skew: 0.110 Prob(JB): 0.449 Kurtosis: 1.990 Cond. No. 43.3 ============================================================================== |
何やら色々出てきました。
勿論すべて大事な指標なのですが、とりあえず\(a\)と\(b\)と\(R^2\)値は確認しておきましょう。
中段にある「coef」と「const」が交わった所にある数字が切片です。今回の例では106.7334です。
「coef」と「temperature」が交わったところにある数字が傾きです。今回の例では39.1031です。
そして、右上にある「R-squared」が\(R^2\)値になります。今回の例では0.808なので、そこそこ信用に値する結果になっていそうです。
いずれもExcelで実行した時と同じ結果が得られているようです。
結果として、アイスクリームの売上を\(y\)、気温を\(x\)とすると、\(y=106.7x+39.1\)という関係があるという答えが出ました。
未知のデータの推測
さて、回帰分析が出来た所で、お次は明日以降の予想気温をもとにアイスクリームの売上を予測してみます。
まあ、先程計算できた式の\(x\)に数値を入れて計算するだけではありますが・・・。
それでは冒頭で読み込んだdf_testを呼び出し、それと先程計算した\(a\)と\(b\)の値を用いて予測売上を計算してみましょう。
|
1 2 3 4 5 |
y_result=[] for i in range(len(df_test.index)): y_tmp = result.params.const + result.params[x_name] * df_test[x_name][i] y_result.append(y_tmp) print(y_result) |
result.params.constには切片が、result.params[●]には●の傾きが格納されています。
上記のプログラムを実行すると・・・
|
1 |
[599.4330734770003, 837.9622816650826, 505.58551615709916, 697.1909456852309, 908.3479496550086] |
df_testの上から順番に\(y\)が計算されました。
あとは以下のようにすれば、Excelに推測結果を書き出すことができます。
|
1 2 3 |
df_test_y = pd.DataFrame(y_result,columns=["y"]) df_result = pd.concat([df_test,df_test_y],axis=1) df_result.to_csv("result.csv") |
冒頭で読み込んだファイルに、\(y\)が追記されたresult.csvが出来ました。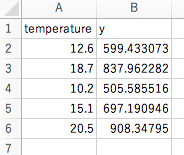
回帰分析結果のグラフ化
折角なので、グラフも書いてみましょう。
|
1 2 3 4 |
import matplotlib.pyplot as plt plt.plot(x, y, 'o') plt.plot(x, result.params.const+result.params[x_name]*x) plt.show() |
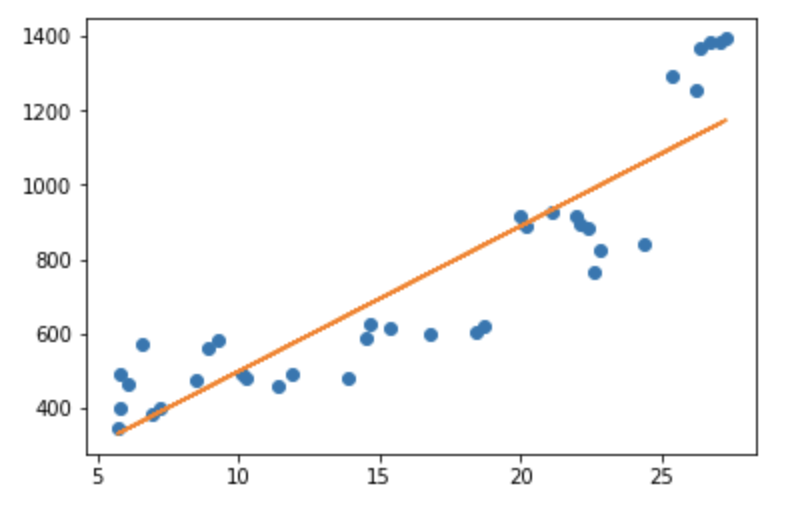
そこそこ良い回帰分析が出来ていそうですね。
単回帰分析であれば、何はともあれグラフを書いてみると、回帰分析の精度が直感的に分かりやすくなって良いと思います。
まとめ
さて、今回はPythonで回帰分析を行ってみました。
流れとしては、まず人間はデータを読み込ませて、\(x\)と\(y\)を指定してあげる。
そして回帰分析自体はコンピュータにやらせて、出てきた結果をどう解釈するかを人間が考える。
・・・おおよそこういった流れとなっています。
ちなみに重回帰分析も、xの列が増えるだけの話ですので、ほぼ同様の手続きで行うことができます。