文章中に含まれる「単語の使われ方」を見て、そこから単語同士の類似性を測ってみます。
そのためには単語を数字のベクトルで表現する必要があるのですが、今回はGoogleが2013年に発表した「Word2Vec」という技術を用いて行ってみます。
当時、「王様」-「男」+「女」=「女王」といった単語の足し算・引き算が出来るとの事で話題になりました。
今では単語をベクトル化する技術は様々ありますが、細かいことは考えずにパッと計算したい時はWord2Vecで充分です。
今回は、PythonでWord2Vecを動かす方法についてご紹介します。
学習モデルの読み込み
何はともあれ、単語をベクトルにするためには「学習モデル」が必要です。
その準備の方法は大きく2通りあります。
1つは、Wikipediaなど大量の多様な文章データから学習させたモデルを使う方法。
多くの場合、Web上で学習済みのモデルを無償公開して頂いている方がおり、無料でダウンロードできます。
モデルの作成が不要なので楽ですが、モデルの読み込みや計算に時間が掛かるなどのデメリットがあります。
もう1つは、「会社内のメール」「Twitter上」など、自分でモデルを作る方法。
○○特化、のようにオリジナルな学習モデルを作ることができますが、モデル作成の手間が掛かったり、データ量が少ないと正しく計算できなくなってしまうなどのデメリットがあります。
それぞれのメリット・デメリットを踏まえ、適切に使い分けて下さい。
以下、Pythonを用いてそれぞれの方法で単語をベクトル化して行きます。
既存の学習モデルを用いる場合
まずは既存モデルを使う場合の方法です。
今回は「東北大学 乾・岡崎研究室」にて公開頂いているモデルを拝借しました。
まずは、このファイルを自身の作業環境にダウンロードします。
任意のディレクトリに配置し、以下のように読み込みます。
|
1 2 3 4 |
#word2vecモデル読み込み import gensim from gensim.models.word2vec import Word2Vec model = gensim.models.KeyedVectors.load_word2vec_format("entity_vector.model.bin", binary=True) |
ダウンロードすると「bin」「txt」の2ファイルありますが、binの方がファイルサイズが小さいのでこちらを使用します。
その際には、オプションの「binary=True」を忘れないように気をつけて下さい。
読み込みに少々時間が掛かる可能性があります。
計算実行の度にモデル読み込みをすると面倒なので、Jupyterなどで別セルを作って実行し、読み込ませた状態で以降の計算を行うことをオススメします。
学習モデルを作成する場合
自分でモデルを作る場合は、人間がデータを準備して読み込ませ、形態素解析しておく必要があります。
手間はかかりますが、オリジナルの学習モデルを作るためですので仕方ありません。
今回は無償公開されている「livedoorニュースコーパス」のデータを全て読み込ませ、学習に使ってみます。
形態素解析は、既存モデルではMeCabを使用しているとの事なので、それに合わせます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
#word2vecモデル作成 import MeCab import glob m = MeCab.Tagger ('-Ochasen') words_all = [] #全ファイルの形態素を格納 for x in glob.glob("text/*/*"): words = [] #読み込んだファイルごとの形態素を格納 with open(x) as f: text = "" next(f) #1行目は飛ばす next(f) #2行目も飛ばす for line in f: text = text + line.strip("\n") #改行は削除 node = m.parseToNode(text) while node: words.append(node.surface) node = node.next words_all.append(words) f.close() #学習 from gensim.models.word2vec import Word2Vec model_new = Word2Vec(words_all) |
データの形式に応じて読み込ませ方は変わりますが、livedoorニュースコーパスの場合は上記のようにすれば読み込めます。
形態素解析できたら、Word2Vecメソッドにそのデータを与えれば勝手に学習してくれます。
単語のベクトル取得
モデルの作成が完了したら、いよいよ単語をベクトル化してみます。
今回は、試しに日本の都道府県名47語をベクトル化して、その傾向を調べてみることにします。
まずは、調査したい単語を以下のようにリストに格納しておきましょう。(途中省略)
|
1 |
words=["北海道","青森","岩手",...,"沖縄"] |
既存の学習モデルを用いた場合
|
1 2 3 4 5 6 7 |
word_list=[] vec_list=[] for i in range(len(words)): if len(words[i]) > 1: if words[i] in model.vocab: word_list.append(words[i]) vec_list.append(model[words[i]]) |
ベクトルの取り方はmodel[“単語”]とするだけです。
ちなみに、調べたい単語が、学習済の単語で無ければ計算しようがありません。
なので、ifで「単語が存在するのか」をまずチェックして、それがOKならばベクトルを取得するようにしています。
学習モデルを作成した場合
|
1 2 3 4 5 6 7 |
word_list=[] vec_list=[] for i in range(len(words)): if len(words[i]) > 1: if words[i] in model_new.wv.vocab: word_list.append(words[i]) vec_list.append(model_new[words[i]]) |
処理は同様ですが、単語の存在チェックの関数が少し違います。
学習モデルの形式によって変わるようですが、もし「(モデル名).vocab」で取得できなければ上記のように「(モデル名).wv.vocab」を使って下さい。
また、自作の学習モデルを使う場合は、「学習済みの単語」に「調べたい単語」が存在しない可能性が高くなります。
現に、libedoorニュースコーパスには「和歌山」が存在しませんでした。
結果のグラフ化
さて、ベクトル化できたので、この後は自由自在です。
今回は、主成分分析をして単語の近さを視覚化してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#主成分分析の実行 import pandas as pd import numpy as np from sklearn.decomposition import PCA pca = PCA(n_components=2) pca_vec_list = pca.fit_transform(vec_list) X = pca_vec_list[:,0] Y = pca_vec_list[:,1] #グラフ化 import matplotlib.pyplot as plt plt.figure(figsize=(12, 12)) plt.rcParams["font.size"] = 15 plt.scatter(X,Y,s=10) #点に説明を付与 for i,(x_name,y_name) in enumerate(zip(X,Y)): plt.annotate(word_list[i],(x_name,y_name)) plt.show() |
デザインはお好みで。では結果を見てみます。
既存モデル

見てみると、「東京」「大阪」「京都」といった都心部が右下に固まっており、近い単語と判断しています。
「北海道」と「沖縄」も、地理的には遠くても意味は近いと出ています。
「広島」「長崎」が近いことも考えさせられますね。
「地理」の近さではなく、「意味」の近さとしてはなかなか納得感のある結果が得られているのでは無いでしょうか。
自作モデル
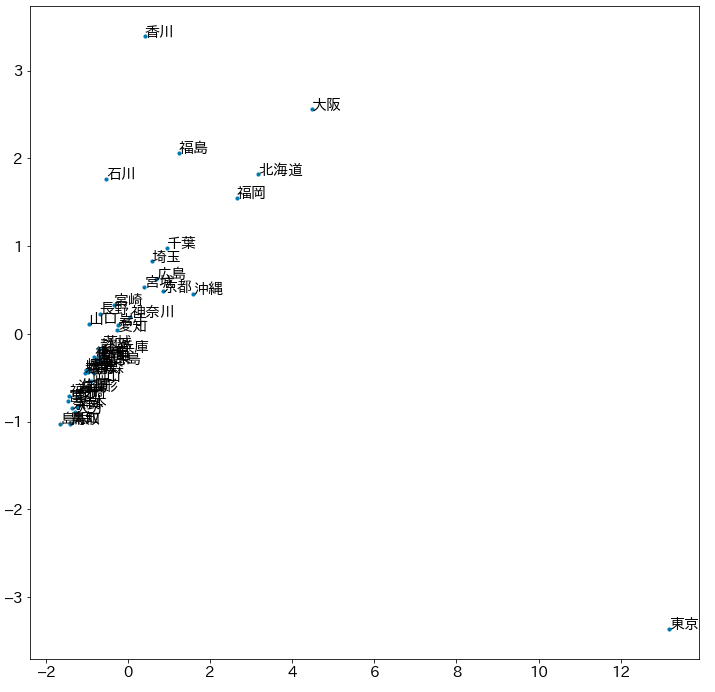
ほとんど団子状態です。
既存モデルに比べたら圧倒的に学習データが少ないので、これらの単語が「県名」という仲間であるという面くらいしか捉えられなかった可能性はあります。
しかし、「東京」だけは圧倒的に特別な単語だと捉えられていますね。
「香川」が特徴的だと評価されている点も気になる所です。
本記事ではこれ以上の細かい分析は行いませんが、livedoorニュースコーパスで「東京」や「香川」の現れている記事がどんな記事なのか、実際に見てみると面白い示唆が得られるかもしれません。
まとめ
このように、単語を数値ベクトル化すると、我々が文章を読んだだけでは分からない示唆を与えてくれます。
例えば社内アンケートやメール文なんかで解析すると、その会社の問題点などが見えてくる事もあります。
あくまでも「示唆」を考えるのは人間ですが、それを考えるネタを与えてくれる方法としてはかなり使えるものですので、ぜひ活用してみてください。
単語でなく、文章をベクトル化する方法は以下にて説明しています。