
Pythonで機械学習のひとつSVM(サポートベクターマシン)を実行してみます。
1963年に基礎理論が発表されてから未だに使用される事の多い、機械学習の代表的手法です。
サポートベクターマシンとは
以下のように、座標平面上に2種類のデータがあるとします。
これを直線でうまい具合に分割してみましょう。
以下のように色々と実験してみます。
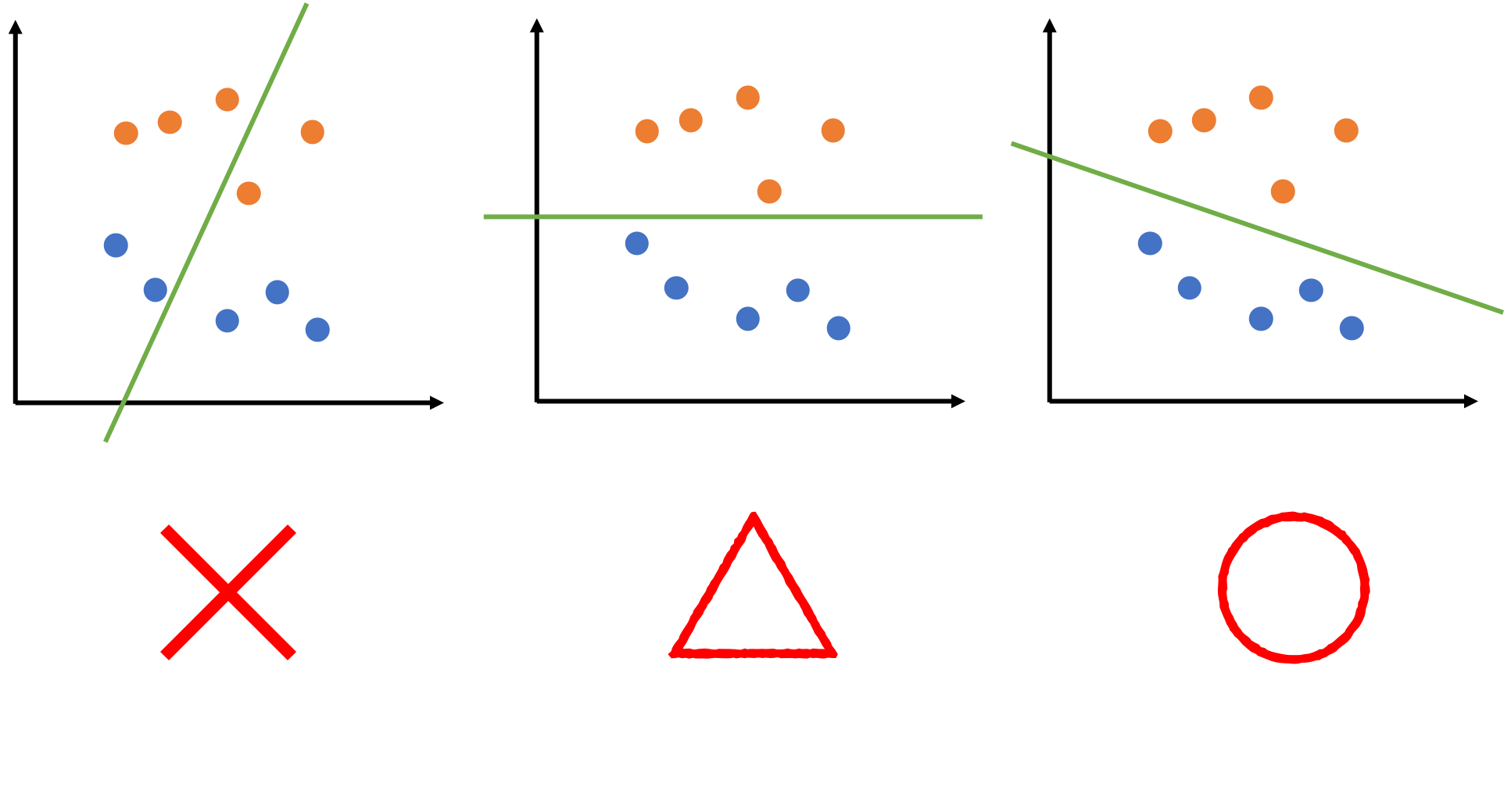
真ん中の図も2分割出来ていますが、線と点がギリギリです。
左の図は、点と線の距離に余裕があり、真ん中の図よりも良い分け方に見えます。
このように、うまくデータを分割する線はどこかを計算してくれる機械学習手法がサポートベクターマシンです。
このように線を引くことができれば「線で分けたこっち側か、あっち側か」を見るだけで未知のデータがオレンジ色のグループに属するか青色のグループに属するかを推測する事ができます。
上記は「2次元平面上において、直線を用いて領域を2つに分ける」話でしたが、これを拡張して「n次元において、曲線(曲面)を用いて領域をn個に分ける」という問題を解く事もできます。
このように、SVMは様々な分類問題を解くための機械学習手法となります。
Pythonによる実行
pythonのsklearnモジュールを用いれば、次元数やクラス数などは深く気にせずにSVMを実行することができます。
早速やってみましょう。
データの読み込み
今回は、scikit-learnにサンプルデータとして用意されている乳がん患者のデータセットを用いてみます。
以下のように読み込みます。
|
1 2 3 4 |
#データの読み込み from sklearn.datasets import load_breast_cancer dataset = load_breast_cancer() X, y = dataset.data, dataset.target |
読み込んだ後に、説明変数である「X」と目的変数である「y」をそれぞれ取得しています。
SVMの実行
SVMの性能を確認するため、「学習データ」と「評価データ」に分割します。
「学習データ」で座標上に良い感じの線を引き、「評価データ」でその線がどれほど正しいのかを確かめます。
人為的に分割しても良いのですが、sklearnには「train_test_split」という大変便利なパッケージがあるので、それを使います。
|
1 2 3 |
# データセットを学習用と検証用に分割する from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=0, stratify=y) |
「test_size」は「評価データ」の比率です。今回は0.2を指定したので、全データの2割が「評価データ」に振り分けられます。
「shuffle」はデータの順番をランダムにするオプションです。今回で言えば、「2割」を上から順番に取るのではなく、ランダムにピックアップします。データが固まっていると分割した2データの傾向が異なってしまう可能性もあるので、基本的に指定したほうが良いかと思います。
「random_state」は乱数シードの指定で、数値を指定すれば毎回固定の乱数が使われ、しなければ毎回乱数を発生させて実行のたびに違う結果が得られます。
「stratify」は学習データと評価データにyが均等に振り分けられるようにするオプションです。学習データに「悪性」ばかり固まったりする事が無くなります。
では、この学習データを使ってSVMを実行してみましょう。
それには以下のようにします。
|
1 2 3 4 |
# 学習 from sklearn.svm import SVC svc = SVC(kernel='linear', random_state=0) svc.fit(X_train, y_train) |
「kernel」には分割に使う線を指定しますが、今回はシンプルに直線(平面)で分割してみますので「linear」を指定しています。
ちなみに、何も指定しないと、「RBFカーネル」という方法で分類が行われます。
性能評価
「学習データ」「評価データ」それぞれについて、どれほどの判別精度が出ているか見てみます。
|
1 2 3 4 5 6 7 8 9 10 |
# 評価 from sklearn.metrics import accuracy_score y_train_pred = svc.predict(X_train) train_acc = accuracy_score(y_train, y_train_pred) print('train score :',train_acc) y_test_pred = svc.predict(X_test) test_acc = accuracy_score(y_test, y_test_pred) print('test score :',test_acc) |
結果を見てみると。。。
|
1 2 |
train score : 0.9692307692307692 test score : 0.956140350877193 |
学習データでは約96.9%の正解率、評価データでは約95.6%の正解率で、非常に良い分類精度が出ているようです。
結果の図示
結果を図にしてみます。
方法は色々とありますが、主成分分析により次元数を2に落とし、良性か悪性かを色分けして表示してみます。
|
1 2 3 4 5 6 7 8 9 10 11 |
from sklearn.decomposition import PCA import matplotlib.pyplot as plt pca = PCA(n_components=2) vecs_train = pca.fit_transform(X_train) plt.scatter(vecs_train[:,0], vecs_train[:,1],s=4, c=y_train, cmap='jet') plt.show() vecs_test = pca.fit_transform(X_test) plt.scatter(vecs_test[:,0], vecs_test[:,1],s=4, c=y_test, cmap='jet') plt.show() |
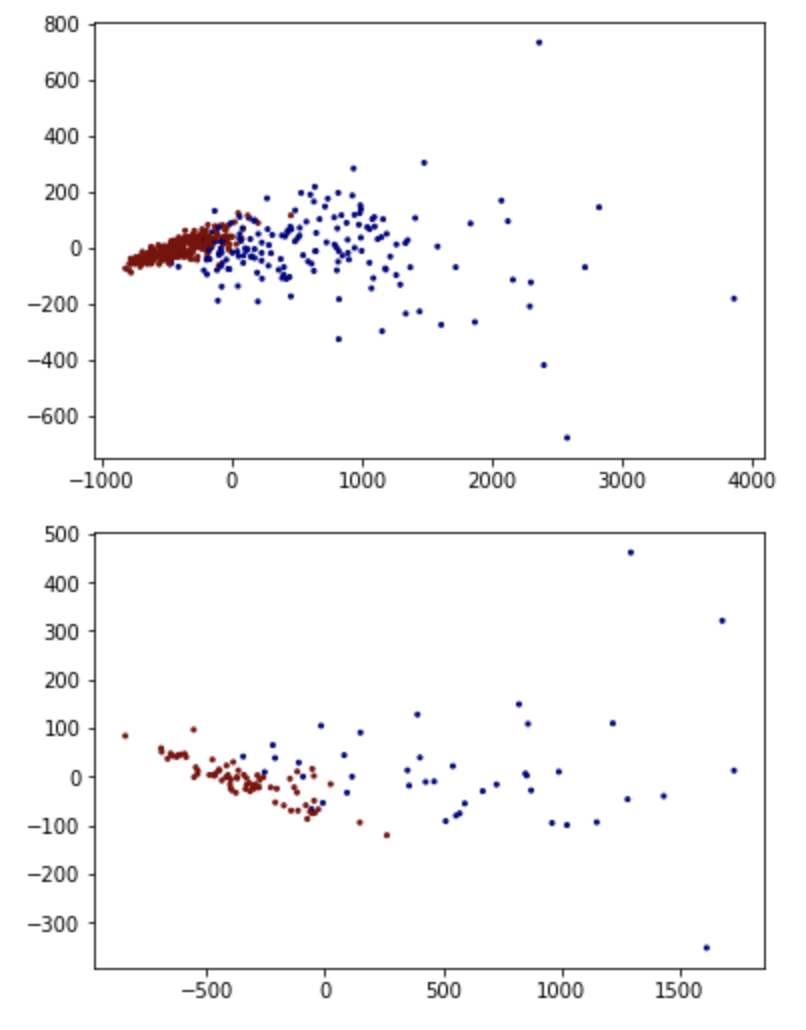
学習データ(上図)も評価データ(下図)も、青色(良性)と赤色(悪性)の位置そこそこ固まっており、やはり良い分類が出来ていそうです。
ちなみに、新規のデータに対して、乳がんかどうか予測するには、以下のようにpredictメソッドに説明変数をリストで与えればOKです。
|
1 2 3 4 |
#予測したいとき pred = svc.predict([[1.0,2.0,9.0,5.0,1.0,1.0,1.0,6.0,2.0,7.0,4.0,1.0,2.0,3.0,9.0, 3.0,3.0,1.0,2.0,6.0,1.0,3.0,1.0,7.0,1.0,3.0,3.0,1.0,3.0,1.0]]) print(pred) |
|
1 |
[1] |
「クラス1」、つまり良性であると推定されました。
終わりに
以上がPythonにおけるSVM(サポートベクターマシン)の実行方法でした。
非常に実行も簡単で性能が出ることの多い機械学習手法ですので、分類タスクを解く際には活用を検討してみてください。





