Pythonを使って、綺麗なヒストグラムを作りましょう。
seabornライブラリのdistplotを使用していきます。
また、環境はJupyter notebookを使用していることを想定しています。
目次
使用データの読み込み
今回は、以下のテストの成績データを使ってみます。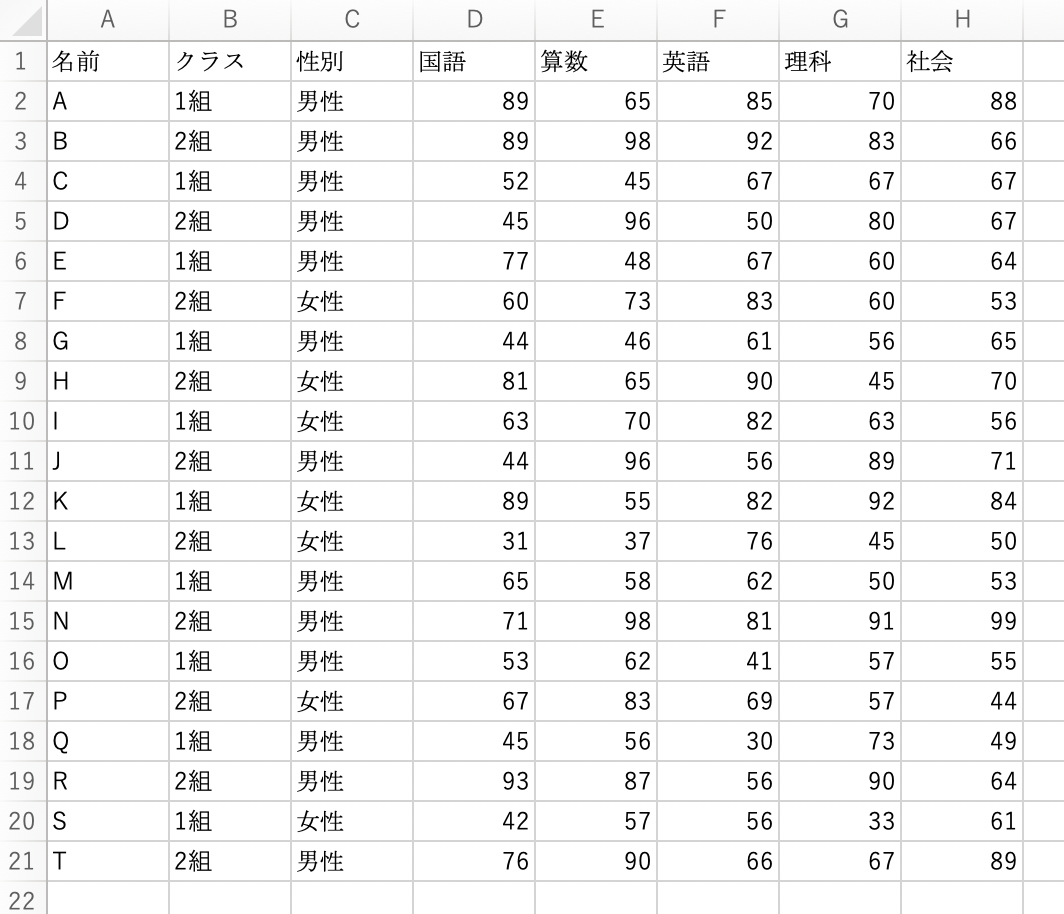
まずは読み込ませましょう。
|
1 2 |
import pandas as pd df_score = pd.read_csv("test_score.csv",index_col="名前") |
ヒストグラムの描画
Pythonでヒストグラムを書く方法は幾つかありますが、seabornを使う方法が最も綺麗な図を作成できると思います。
あまり細かい事に拘らないのであれば、以下のように引数にヒストグラム化したいデータを与えるだけでOKです。
今回は算数のデータでヒストグラムを書いてみます。
|
1 2 3 |
import seaborn as sns sns.set() sns.distplot(df_score["算数"]) |
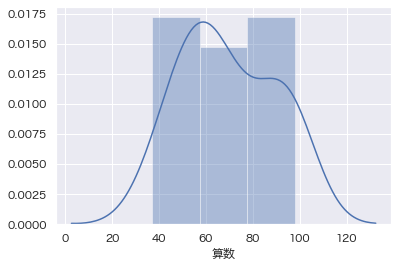
・・・一応、できたみたいです。
デフォルトだと上に曲線が描かれていますが、これはKDE(カーネル密度推定)と言って、ヒストグラムの形状を滑らかに1本の線にしたものとなっています。
ざっとデータの状況を確認したいだけならこれでも良いのですが、どこかに掲載する図にする場合はもう少し整えてみたいですね。
グラフの調整
ヒストグラムをざっと整える方法として、以下の3つの引数を紹介します。
- kde=False・・・カーネル密度関数の曲線を非表示にする
- bins=(数字)・・・棒の本数を指定する
- hist_kws={“range”:(数字A,数字B)}・・・X軸の最小値・最大値を指定する(※kdeを表示している場合は無視されます)
以上3つを適用して、改めてヒストグラムを描画してみます。
今回はカーネル密度関数は不要と思われます。
点数なので表示範囲は0〜100で良いでしょう。
棒は10点刻みがキリが良いので、binsは10にします。
|
1 2 3 |
import seaborn as sns sns.set() sns.distplot(df_score["算数"],kde=False,bins=10, hist_kws={"range":(0,100)}) |
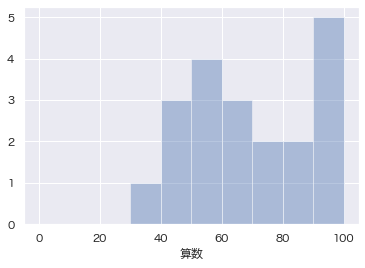
綺麗なヒストグラムになったようです。
重ねて表示する
distplotを連続実行するだけで、複数のヒストグラムを重ねて表示することができます。
試しに、算数のグラフの上に国語のグラフを重ねてみましょう。
|
1 2 3 4 |
import seaborn as sns sns.set() sns.distplot(df_score["算数"],kde=False,bins=10, hist_kws={"range":(0,100)}) sns.distplot(df_score["国語"],kde=False,bins=10, hist_kws={"range":(0,100)}) |
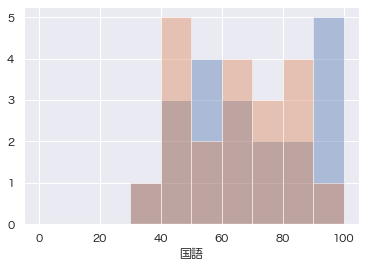
2つが重なり、算数と国語のそれぞれの傾向が分かりやすくなりました。
ただ、あまり重ねすぎると分からなくなるので、2〜3つくらいまでにした方が良いと思います。
これで、無事に見た目の良いヒストグラムが完成しました。