
Pythonを使ってランダムフォレストを実行してみます。
決定木分析を基調とした手法なので、先に決定木分析の記事を読んで頂いてからの方が分かりやすいかもしれません。

ランダムフォレストとは
一言で言えば決定木分析を何度も行い、多数決で最終結果を決める手法です。
しかし同じデータで何回やっても結果は一緒なので、与えた教師データを様々なパターンで部分抽出して、そのそれぞれで決定木を作ります。
同様に説明変数も全てではなく、一部を抽出します。
・・・これを何回も行い、最終的に多数決を取ることによって、どの変数が分類に重要なのかを判断します。
データや変数の抽出は完全にランダムで行い、決定木を沢山作って評価することから、木がたくさん=森ということで「ランダムフォレスト」という手法名が付けられました。
最終的に「分類に重要な変数」を知る事ができ、性能の良い学習モデルが作成される事が多いです。
しかし、最後のアウトプットで決定木自体が出力される訳ではないのでご注意下さい。
学習モデルの作成目的ではなく、実際の決定木を見てデータの傾向を判断したい、という目的ならば通常の決定木分析の方が良いでしょう。
Pythonによる実行
それでは、ランダムフォレストをPythonで実行してみます。
今回は、sklearnに準備されている、アヤメの品種分類のデータセットを用いてみます。
データの準備
sklearnに初期搭載されているデータを読み込ませるのは簡単です。
|
1 2 3 4 |
#データ読み込み from sklearn.datasets import load_iris dataset = load_iris() X, y = dataset.data, dataset.target |
これでXに全ての説明変数、yに全ての目的変数が格納されます。
ExcelやCSVの形式でしたら、決定木分析の記事などを参考にしてpandasを用いてデータを読み込ませて下さい。
データを読み込んだら、教師データと評価データに分割します。
分け方は自由ですが、以下のようにtrain_test_splitメソッドを用いるのが簡単です。
|
1 2 3 |
# データセットを学習用と検証用に分割する from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2,shuffle=True,random_state=0,stratify=y) |
引数についてはSVMの記事で記したのと同様なので、ここでは割愛させて頂きます。
ランダムフォレストの実行
それではランダムフォレストを実行します。
併せて性能評価まで一気に行ってしまいます。
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np from sklearn.metrics import accuracy_score from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators=200,max_depth=3,random_state=0) clf = clf.fit(X_train, y_train) y_test_pred = clf.predict(X_test) acc_score = accuracy_score(y_test, y_test_pred) print(np.round(acc_score,3)) |
分類問題を解くランダムフォレストを実行するにはsklearnのRandomForestClassifierメソッドを使います。
引数の「n_estimators」は決定木の作成回数です。特に決まりはありませんが、デフォルトでは「10回」となっています。
多くても100回程度回しておけば、それ以上はほとんど性能は変わらないかなという感覚です。
「max_depth」は決定木の深さです。
これは初めに人間が決める必要があります。適切な数値はデータや変数の量によっても変わりますが、ひとまず3,5,10あたりで実験してみるのが良いでしょう。
初めに準備した評価用データであるy_testと、作成した学習モデルによる推論結果y_test_predを比較することにより、性能が測れます。
結果を見てみると・・・
|
1 |
0.933 |
93.3%という高い分類性能が出ているようです。
結果(分類に大切な要素)の可視化
先述しましたが、ランダムフォレストでは過程で様々な決定木を作成するので、「最終的な決定木」というものは存在しません。
しかし、その代わりに「分類に大切な要素」を見ることはできます。
今回は要素の重要度を棒グラフで表示してみます。
|
1 2 3 4 5 6 7 8 9 10 11 |
#重要な変数の可視化 import matplotlib.pyplot as plt features = np.array(dataset.feature_names) importances = clf.feature_importances_ indices = np.argsort(importances) plt.figure() plt.barh(range(len(indices)), importances[indices], color='b', align='center') plt.yticks(range(len(indices)), features[indices]) plt.show() |
結果を見てみると・・・
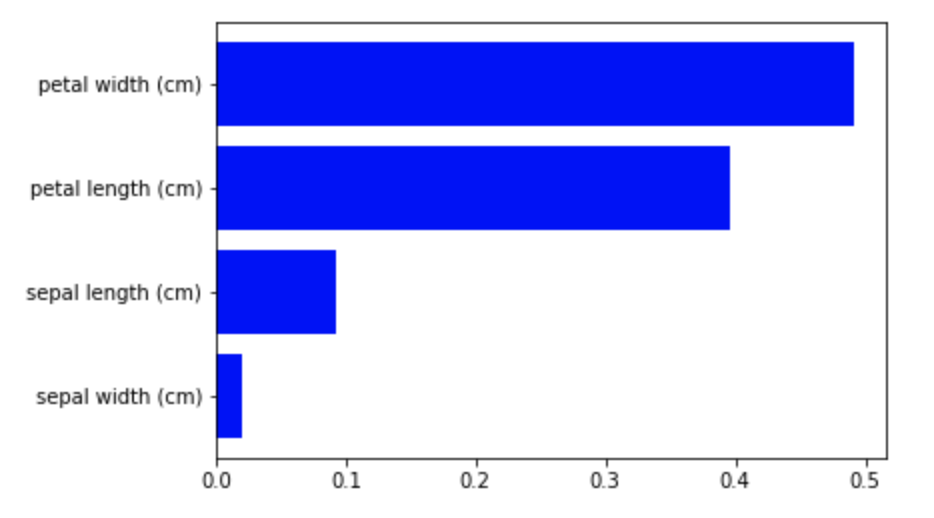
petal width、つまりアヤメの分類には花びらの長さが最も重要な要素である事が分かりました。
おわりに
以上、ランダムフォレストをPythonで実行する方法でした。
決定木分析をパワーアップさせたものがランダムフォレスト、というような解説がなされる場合がありますが、必ずしも決定木分析よりランダムフォレストが優れている、という訳ではありません。
学習モデルを作成したいならばランダムフォレスト。
具体的な「決定木」を見て色々検討したいならば決定木分析、などというように適切に使い分けて下さい。




